



What is Q*, the AI model that broke OpenAI?
Language models enhanced with reasoning are the next big breakthrough in AI

Recent events at OpenAI have brought to daylight one of the projects the company was working on. This project, known as Q*, not only broke OpenAI but also drew attention to what is going on at the cutting edge of AI research, where teams from top AI research labs are working on enhancing large language models with the ability to reason.
In this article, we will explore how top AI labs experiment with enhancing language models with reasoning and the role reinforced learning is playing in these efforts.
Let’s begin by looking at how the human mind operates. In Thinking, Fast and Slow*, Daniel Kahneman introduces the concept of System 1 and System 2 thinking. System 1 is the quick thinker. It excels at easy tasks or things done repeatedly, such as knowing that 2 + 2 equals 4, recognizing a friend's face, or ducking when a ball is thrown at you. System 1 doesn't tire easily and is always ready to respond. System 2, however, is our deep thinker. It is slower than System 1 and comes into play when we need to tackle more challenging problems, like solving a complex math problem, learning a new skill, or making a significant decision. The drawback of System 2 is that it needs more energy and cannot be used all the time.
Large language models, like GPT-4 or Claude, are at the System 1 level today. They are good at quickly producing an answer to a prompt that in most cases is correct. However, these language models don't actually "know" which answers are correct. They are designed to predict the most likely next word based on all the preceding words. This simple idea, when scaled up to billions of parameters and trained on almost everything humanity has ever written, and then finetuned by humans to behave as expected, led to the creation of modern language models like GPT-4. But there is no real reasoning within these models (and if there is, it's quite limited).
One of the biggest challenges in AI research today is how to create an equivalent of System 2 for language models thus giving them the ability to reason, evaluate their thoughts and come up with not only the optimal solution to the problem but also to propose a new and creative solution.
Every big AI research lab, from DeepMind to OpenAI, is currently working on this problem. Each has its own approach to enabling reasoning in language models but all approaches seem to converge on integrating large language models with reinforcement learning.
Tree of Thoughts
In May 2023, a group of researchers from Princeton University and Google DeepMind published a paper where they were exploring the idea of the Tree of Thoughts. Instead of producing one result, the Tree of Thoughts approach would take some number of initial “thoughts” (which the paper defines as “coherent units of text”) and explore where would those thoughts take the AI agent. In a way, it is very similar to what a human would do when presented with a difficult problem that requires thinking. Just like a human, the agent considers multiple paths of reasoning and evaluates them. Some of those paths will lead nowhere but some will lead closer to the correct solution.
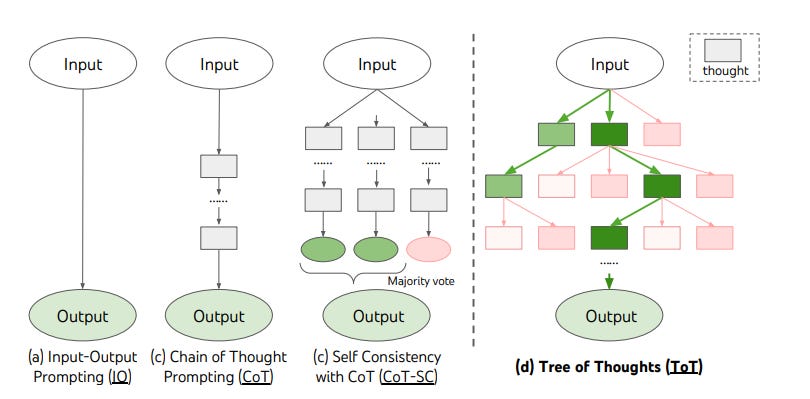
Researchers then tested the Tree of Thoughts approach against three tasks that require non-trivial planning or search: Game of 24, Creative Writing, and Mini Crosswords. In Game of 24, they found that a language model enhanced with Tree of Thoughts was able to successfully solve 74% of tasks while GPT-4 with chain-of-thought prompting only solved 4%. In Creative Writing tests, humans evaluating texts generated by language models preferred the ones generated by a model with the Tree of Thoughts. In solving Mini Crosswords, Tree of Thoughts got a success rate of 60% while the other methods like Chain of Thought Prompting scored no more than 16% success rate. In all cases, adding some kind of self-reflection into the model resulted in significant performance improvements.
If you're enjoying the insights and perspectives shared in the Humanity Redefined newsletter, why not spread the word?
Q*
OpenAI is also working on enhancing language models with some form of reasoning and self-reflection. According to a report from Reuters, it was the research in this area and a new model that came out of it, known as Q* (pronounced as Q-star) that began the chain of events that resulted in the schism at OpenAI.
The first step OpenAI made towards introducing reasoning was presented in Training Verifiers to Solve Math Word Problems paper, published in November 2021. In that paper, researchers asked a language model to generate answers to math problems from GSM8K, a dataset of 8,500 high-quality linguistically diverse grade school math word problems. These answers were then evaluated by a verifier which returned a solution that ranked the highest. This approach resulted in a massive improvement in performance. The paper reports that a model with 6B parameters was able to slightly outperform a 30x larger, 175B parameter fine-tuned model (that’s equivalent to Mistral 7B or Llama2-7B outperforming GPT-3 on math tests). It is worth noting all of this improvement happened during the tests - the model did not get any additional pretraining or fine-tuning. However, there was a flaw in this model. Sometimes, the model reached a correct final answer using flawed reasoning, leading to false positives.
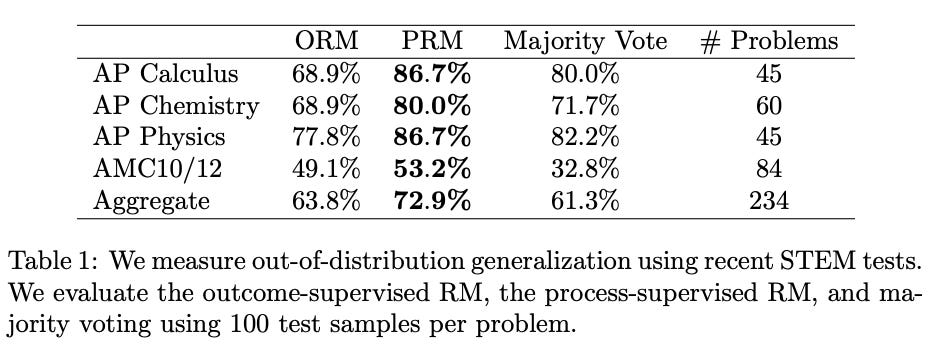
In July 2023, OpenAI published a paper titled Let’s Verify Step by Step that addressed the false positives issue from the previous paper. The main idea tested in this paper was to score the model not on the outcome (known as outcome-supervised reward models, or ORMs) but on examining the process in which the model reached the outcome (process-supervised reward models, or PRMs).
The PRM model was trained to evaluate each step in the reasoning process and got very good at spotting mistakes from answers generated by a generator (GPT-4). When there were no mistakes in the reasoning process, the answer was marked as correct. This new, process-oriented reward model solved 78% of problems from a representative subset of the MATH, a dataset of 12,500 challenging math problems.

The paper also shows that this approach works not only for math problems but also for other subjects such as chemistry and physics. In each case, focusing on rewarding the correct steps in reasoning yielded better results than just focusing on the answer and the majority vote.
The Let’s Verify Step by Step paper has one interesting line: “Although finetuning the generator with RL is a natural next step, it is intentionally not the focus of this work.” From the pieces we have available, we can assume that Q* was the follow-up to the model introduced in Let’s Verify Step by Step and added the “natural next step” - reinforced learning - to the mix. The name itself, Q*, also hints at this possibility. Q can be a reference to Q-learning, an important technique in reinforcement learning. Q-learning is like teaching a computer to play a game by letting it practice and learn from its own experiences. Over time, it figures out the best moves to make in different situations, so it can win the game more easily. Alternatively, Q can refer to Q-values, another concept from reinforced learning, that help the computer decide which paths (or actions) are the best to take to get the most reward in the end. The “star” in Q* can be a reference to a similarly pronounced A* algorithm (a powerful path-finding algorithm) or it can just mean “optimal” (asterisks in mathematics often indicate that something is optimal). In any case, the name Q* has lots of connections to reinforced learning.
For a more detailed look into the recent papers from OpenAI on enhancing language models with reasoning, I highly recommend checking out Q* - Clues to the Puzzle? video from AI Explained. The video does an amazing job piecing together the clues on what Q* could be.
Is artificial general intelligence around the corner?
I’m reminded of an interview Demis Hassabis gave in The Verge when he said that “generative AI is now the “in” thing, but I think that planning and deep reinforcement learning and problem-solving and reasoning, those kinds of capabilities are going to come back in the next wave after this, along with the current capabilities of the current systems”. In the same interview, he also says: “one could imagine AI systems that are capable of actually conversing with themselves or critiquing themselves. This would be a bit like turning language systems into a game-like setting, which of course we’re very expert in and we’ve been thinking about where these reinforcement learning systems, different versions of them, can actually rate each other in some way.”
In the paper on the Tree of Thoughts, researchers dealt with simple trees and employed classic tree traversal algorithms like breadth-first search or depth-first search. For more complex problems, a larger tree representing all possible "thoughts" would need to be explored. At that point, classic algorithms become impractical and a new approach is needed. This is essentially the same problem researchers at DeepMind faced when they took on the challenge of creating an AI that can play Go. Their efforts culminated in the development of AlphaGo, which subsequently defeated the Go world champion Lee Sedol.

AlphaGo was able to create new and creative moves, such as the famous Move 37. Sometime later, DeepMind released AlphaZero, a completely new AI that learned how to play Go, chess and shogi on its own and created completely new ways of playing these games free of human traditional ways of thinking.
The next big thing in AI research is planning and reasoning. Top AI labs are experimenting with reinforced learning to bring those abilities to language models. Adding an equivalent of System 2 thinking to AI models could be the key to enabling AI to go beyond just imitating humans and to be truly creative. Language models enhanced with reasoning could come up with solutions that humans may never stumble upon, producing Move 37-like breakthroughs outside the human ways of thinking. At that point, many can make a valid argument that artificial general intelligence has been created.
*Disclaimer: This link is part of the Amazon Affiliate Program. As an Amazon Associate, I earn from qualifying purchases made through this link. This helps support my work but does not affect the price you pay.
Thanks for reading. If you enjoyed this post, please click the ❤️ button or share it.
Humanity Redefined sheds light on the bleeding edge of technology and how advancements in AI, robotics, and biotech can usher in abundance, expand humanity's horizons, and redefine what it means to be human.
A big thank you to my paid subscribers, to my Patrons: whmr, Florian, dux, Eric, Preppikoma and Andrew, and to everyone who supports my work on Ko-Fi. Thank you for the support!